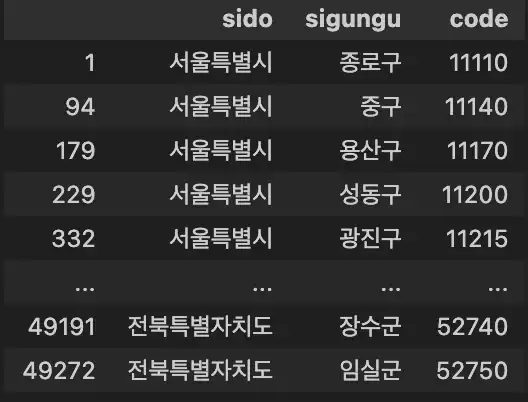
pandas를 이용하여 csv파일 필터링하기
법정동 코드를 사용해야 할 일이 생겨서 공공데이터 포털에서 csv 파일을 다운받았다
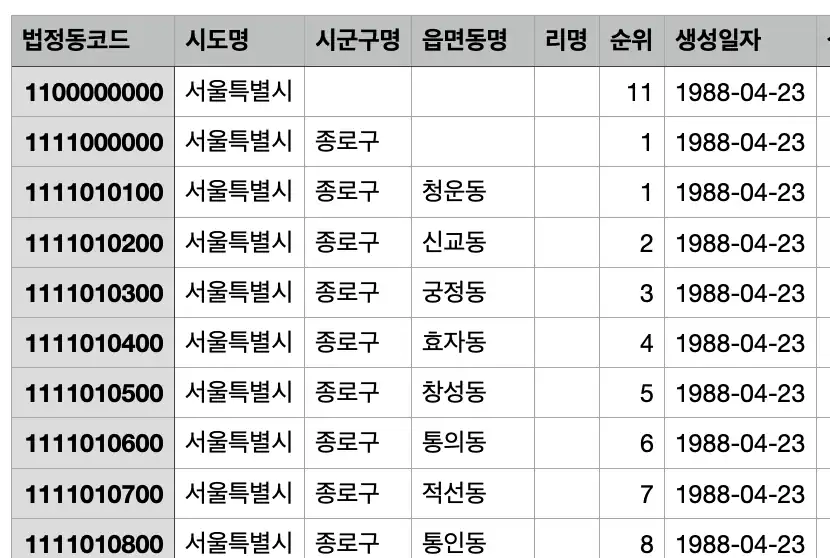
필요한 데이터는 법정동 코드 앞의 5자리, 시도명, 시군구명이다. 그러므로 시군구명이 없는 데이터는 삭제하고, 중복도 없애야 한다. 법정동 코드 앞의 5자리는 구 혹은 군을 식별한다. 지역마다 구나 군 이름이 같은 곳이 존재할 수 있기 때문에 법정동코드를 이용해 중복데이터를 제거하여야 한다.
sqlite를 사용도 간단하겠지만 과정 중간 확인이 편하도록 주피터 노트북 환경에서 파이썬을 사용하였다.
python3 -m venv venv
source venv/bin/activate
pip install pandas터미널에서 파이썬 가상환경을 생성 후 진입한다. pandas를 설치 후 한영전환이 귀찮으니 csv 파일에서 사용할 항목명을 영어로 바꿨다.

import pandas as pd
csv = pd.read_csv('region.csv')pandas 패키지를 불러온후 csv 파일을 읽어서 변수에 저장하였다.

일단 sigungu 항목이 없는 데이터들을 삭제 해야겠다.
has_sigungu = csv['sigungu'].notna()notna 함수는 boolean 시리즈 를 리턴해주는데 지금의 경우 인덱스와 함께 sigungu 값이 있으면 True 아니면 False 를 반환한다.
data_with_sigungu = csv[has_sigungu].copy()sigungu 항목을 가지고 있는 데이터만 복사해서 변수를 생성한다. 데이터를 참조하고 있는 슬라이스를 변경할 때 생기는 에러를 방지하기 위해 copy 를 사용한다.
data_with_sigungu['code_5'] = data_with_sigungu['code'].astype(str).str[:5]code 항목의 앞 5자리만 잘라서 code_5항목을 만든다

filtered_data = data_with_sigungu.drop_duplicates(subset='code_5')code_5 를 이용하여 중복을 제거한다.
final_data =filtered_data.drop(columns=['code', 'dong', '리명', '순위', '생성일자', '삭제일자', '과거법정동코드'])
final_data = final_data.rename(columns={"code_5": "code"})
final_data.to_csv('region_filtered.csv', index=False)사용하지 않는 항목은 삭제후 code_5 를 code 바꾼다. 마지막으로 바뀐 데이터를 이용해 csv파일을 새로 만든다